The following is a cross-post from the Deep Origin blog.
Today, I’m proud to announce the beta release of Deep Origin’s first product: the ComputeBench. The ComputeBench is a cloud-based environment for interactive analysis in computational biology and bioinformatics. It’s designed from the ground up for computational scientists – providing you the compute and storage resources you need, the software packages you expect, and tools for seamless collaboration with your team, all in a secure, backed-up and scalable platform.
We’re building Deep Origin for teams of computational scientists to work in a collaborative, cloud-based environment without worrying about DevOps and IT. In short, our mission is to let scientists focus on science. What we’re releasing today is the first stop in that longer-term vision. Read on to learn more about ComputeBenches, or check out the product page, pricing, and request access.
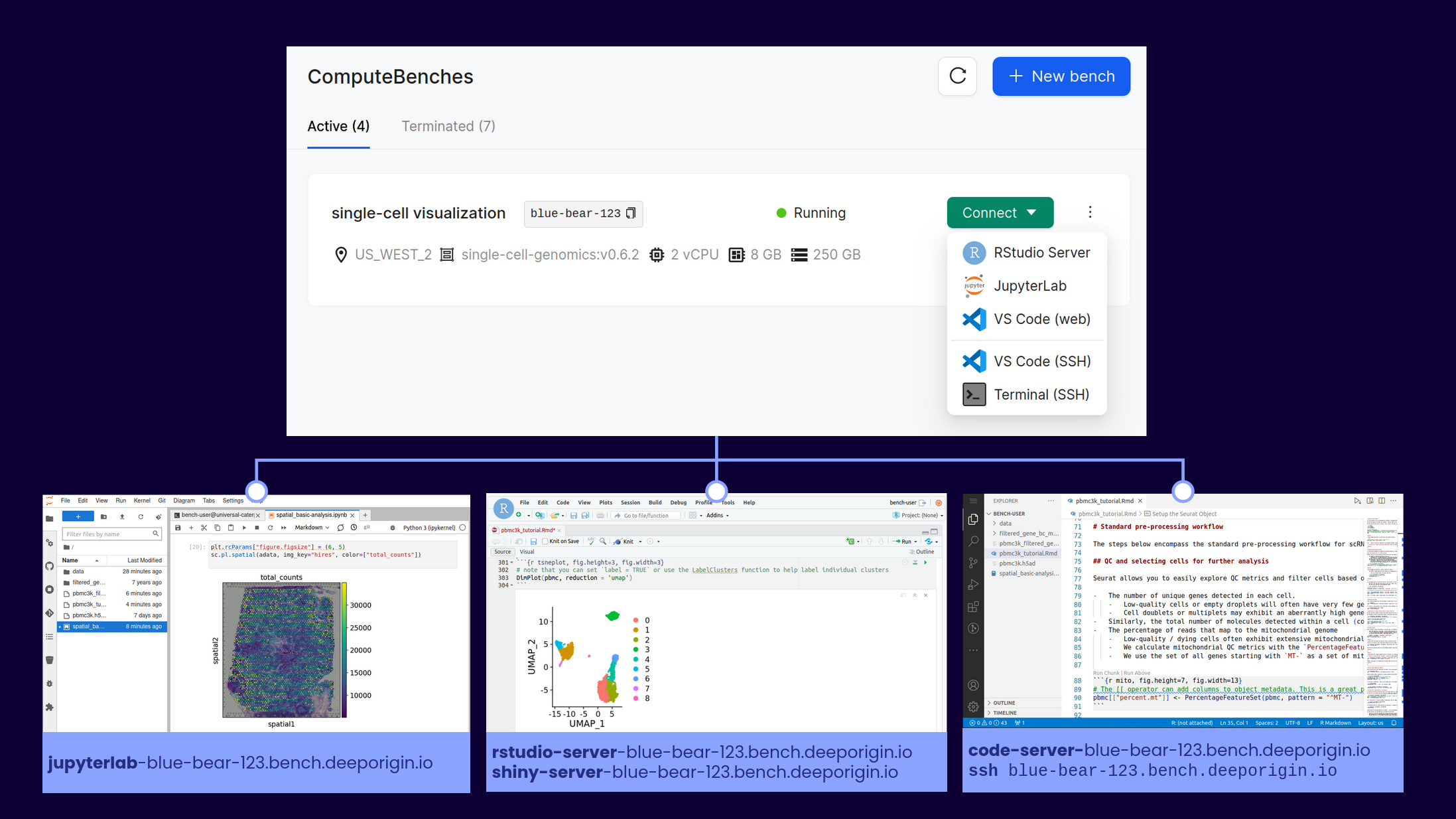
After starting a ComputeBench, it’s one click to drop into the development environment you’re most comfortable with. Computational power, storage, and hundreds of packages are available at your fingertips!
Two trends in biological discovery highlight the importance of developing better tooling for computational biology:
- Biological discoveries are increasingly driven by massive amounts of heterogeneous data. Look no further than the move to single-cell, spatial, long read, or multi-omic profiling, or the promises of the newest instrument vendors.
- Biological discoveries are increasingly collaborative. In both academia and industry, science doesn’t happen in a vacuum, especially when an analysis spans different modalities and areas of expertise.
Meanwhile, tools for collaborative computational biology at scale are lacking, and scientists frequently waste hours or days solving problems that we are all too familiar with. How long have you spent troubleshooting a package installation, setting up the right infrastructure and permissions to share data with a collaborator, or reproducing an analysis from a publication? How many teams have built undifferentiated cloud infrastructure just to get to the point that they can start to do their job?
We built the ComputeBench for these scientists. We want to give every scientist superpowers to scale their analysis, without the boring stuff getting in the way. A ComputeBench has the following key features:
- Scalable hardware: from 2-192 vCPU, 4-1536 GB of RAM, up to 16 TB of local persistent storage, and NVIDIA GPUs if you need them.
- Software blueprints: collections of hundreds of pre-installed, validated, and versioned tools for different scientific domains. Use the tools in the blueprints, or use them as a jumping off point to customize and create your own environment. Examples of our blueprints include metagenomics, RNA sequencing, and single-cell sequencing.
- Interact the way you want: Each blueprint provides a number of user-friendly web-based applications, like JupyterLab, RStudio, VS Code server, R Shiny, or CELLxGENE. You can also connect over SSH, and you have root access to modify your bench as you see fit.
- Storage volumes: performant, scalable storage that can be accessed by all of your ComputeBenches to share data among your team.
- Credential and secret management: Store your secrets and preferences, and automatically load them in every ComputeBench that you create. Share team-level variables and secrets, as well.
- Usage and cost controls. Automatically stop idle ComputeBenches, and view transparent, up-front pricing before you create any resources.
- Invoices for humans. Deep Origin customers receive invoices in terms that are easy to understand and traceable to a particular user or ComputeBench.
ComputeBenches provide the best experience for interactive analysis in computational biology – and we bet you’ll feel the same way. To get started, we’re offering new users $500 in credits to try working on the Deep Origin platform. Since much of the benefit of working on our platform comes when you are working with your team members, we’ll add $500 for each regular user you bring on to your organization, as well.
Claim your $500 in credits here.
Finally, we’re always looking for ways to improve the platform. Next on our roadmap are features allowing users to submit their own software blueprints for use within their organization, and tools to manage data in buckets, both hosted by Deep Origin and elsewhere. If you have feature requests, suggestions of packages to add to a blueprint, or other feedback, please let us know.